Simple ordinary least squares regression (SOLSR) means the following. Given data  ,
,  , find a line in
, find a line in 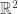 represented by
represented by  that fits the data in the following sense. The loss of each data point
that fits the data in the following sense. The loss of each data point 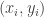 to the line is
to the line is
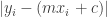 for every
for every  ,
,
so we find 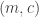 that minimizes the loss function
that minimizes the loss function
![\displaystyle \sum_{i=1}^N [y_i - (mx_i + c)]^2.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_%7Bi%3D1%7D%5EN+%5By_i+-+%28mx_i+%2B+c%29%5D%5E2.&bg=ffffff&fg=333333&s=0&c=20201002)
See here for a closed-form of the minimizer . Instead of SOLSR, one can consider the distance between a data point and a line in as the loss. Notice that is not the distance from to unless 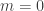 . Then the new least squares problem can be formulated as follows.
. Then the new least squares problem can be formulated as follows.
A general line in can be expressed as  where
where 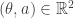 . Thus the distance between and this line is
. Thus the distance between and this line is
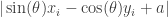 for every .
for every .
Hence we want to find  that minimizes the loss function
that minimizes the loss function
 .
.
Notice that, not only SOLSR, this problem also has a lot of real-life applications. It turns out there is still a closed-form for , and we will derive it. There is a high chance that the answer can be found somewhere, but we could not find it so far. Also it is a good exercise for Hong Kong students who know Additional Maths, although the subject disappeared.
Setting the partial derivative 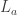 to be zero one has
to be zero one has

which implies
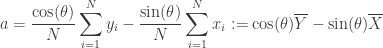 .
.
Using the formulae  and
and  , one has
, one has

where
 .
.
Plugging in the above expression of  into the above formula, we reach
into the above formula, we reach
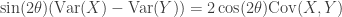
where
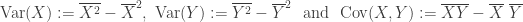 .
.
It implies the formula
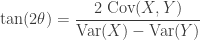 ,
,
which concludes the result:
Theorem 1. The minimizer of the loss function 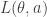 satisfies
satisfies
and  .
.
In particular the point  lies on the best fitted line
lies on the best fitted line  .
.
We leave to the readers to work on the high-dimensional cases, and the case using weighted data.

